
Reklama
Zuckerberg „zajumał” książki? AI uczy się na pirackich bazach, a polscy autorzy są wśród okradzionych
06/04/2025 20:52

Spis treści
- Sztuczna inteligencja: cud technologii czy największa kradzież XXI wieku?
- Rosyjski ślad: LibGen i spółka
- Jak to działa? Korpus, tokeny, miliardy dolarów
- Polska literatura w sidłach AI
- Gdzie jest Grok i Elon w tym bałaganie?
- Konsekwencje? Raczej nie dla autorów
- Czy AI będzie uczciwa? Może polski PLLuM będzie wzorcem
- Co możemy zrobić jako czytelnicy i twórcy?
- Słowniczek AI
Czy sztuczna inteligencja uczy się na kradzionych książkach? Okazuje się, że modele AI takie jak ChatGPT czy LLaMA od Mety trenowane są na danych z pirackich baz, takich jak Library Genesis. Projekt Books3, zawierający 183 tysiące książek, w tym dzieła Olgi Tokarczuk, Doroty Masłowskiej i Szczepana Twardocha, stał się kluczowym zasobem. Meta, firma Marka Zuckerberga, miała sięgać po te nielegalne źródła, by zaoszczędzić na kosztach licencji. Polscy autorzy czują się okradzeni, a Unia Literacka pyta ironicznie: „Czy Twoje książki też ukradli?”. Czy czeka nas fala pozwów i jak na to zareaguje Polska?
Sztuczna inteligencja: cud technologii czy największa kradzież XXI wieku?
Rozwój AI przyspiesza tak mocno, że trudno nadążyć. Modele takie jak ChatGPT, LLaMA od Mety, czy BERT od Google potrzebują miliardów słów, by nauczyć się języka. I tu zaczyna się jazda: okazuje się, że wiele z tych słów pochodzi z... pirackich baz danych, gdzie trafiły bez wiedzy i zgody autorów. Meta – firma Marka Zuckerberga – według dokumentów sądowych sięgnęła po zasoby takich pirackich platform jak Library Genesis (LibGen), Z-Library, Anna’s Archive i Bibliotik. Największą sensacją jest jednak projekt Books3, który zawierał aż 183 tysiące książek – w tym dzieła Olgi Tokarczuk, Doroty Masłowskiej i Szczepana Twardocha.
Rosyjski ślad: LibGen i spółka
Niektóre z baz danych, z których miał korzystać projekt Books3, mają pochodzenie rosyjskie. Szczególnie Library Genesis (LibGen), powstała około 2008 roku w Rosji, uchodzi za największą piracką bibliotekę cyfrową świata, zbierającą podręczniki, literaturę piękną i publikacje naukowe. Choć formalnie nie powiązana z rządem rosyjskim, przez lata działała bez większych przeszkód na rosyjskich serwerach i z rosyjskimi operatorami. Podobnie Z-Library, choć globalna, była często hostowana w regionach byłego ZSRR. W 2022 r. FBI dokonało głośnego zatrzymania jej twórców – obywateli Rosji.
Jak to działa? Korpus, tokeny, miliardy dolarów
By AI mogła odpowiadać mądrze na pytania, musi się najpierw naczytać. Ale nie stu książek. 15 bilionów tokenów – tyle zużyła Meta przy trenowaniu LLaMA 3. Im więcej danych, tym „mądrzejszy” model. A najlepsze dane? Książki. Dopracowane, stylistycznie bogate, bez błędów. Idealne do trenowania AI. Tyle że… droga na skróty prowadzi przez pirackie źródła. Koszt wytrenowania takiego modelu to dziesiątki, a nawet setki milionów dolarów. W tym świetle zakup licencji na książki wydał się Meta „zbyt drogi i czasochłonny”. A przecież wszystko można znaleźć w sieci – za darmo.
Polska literatura w sidłach AI
W Books3 odnaleziono książki polskich autorów, także w tłumaczeniach na angielski. Znajdziemy tam m.in.:
- „Bieguni” Tokarczuk (w wersji „Flights”),
- „Król” Twardocha (polski, angielski, węgierski),
- „Wojna polsko-ruska…” Masłowskiej. Reakcje?
Unia Literacka zapytała ironicznie na Instagramie: „Czy Twoje książki też ukradli?”. A pisarka Grażyna Plebanek wprost: „Czuję się okradana. To największa kradzież dzieł w historii ludzkości” – cytat z „Gazety Wyborczej”.
Gdzie jest Grok i Elon w tym bałaganie?
Zabawne (albo intrygujące): AI Grok od Elona Muska jako jedyna nie znalazła się w centrum tej burzy. Czy to przypadek, czy może efekt... dobrze rozegranej polityki? W sieci pojawiają się spekulacje, że xAI Elona Muska korzysta z mniej kontrowersyjnych danych lub po prostu uniknęła ataków prawnych, bo Musk – otwarcie wspierający Trumpa – nie jest obecnie „na celowniku” tych samych środowisk, co bardziej liberalny Zuckerberg. Czyli: gra o AI to nie tylko dane, ale i polityka.
Konsekwencje? Raczej nie dla autorów
Czy autorzy dostaną pieniądze? Raczej nie. Wzorem sprawy Google Books, wszystko może skończyć się na: wielkich pozwach zbiorowych (już trwają w USA i Francji), ugodach poza sądem (żeby nie robić dymu), i milionowych wypłatach dla prawników, a nie dla twórców. Google też skanowało książki „dla nauki”. I choć sąd finalnie uznał to za „fair use”, ugody i koszty obrony sięgnęły dziesiątek milionów dolarów.
Jeśli Meta obroni się argumentem "fair use" (dozwolonego użytku) w sądzie, kwota odszkodowania będzie znacznie niższa niż szacowany koszt nieopłaconych licencji, ponieważ "fair use" w USA pozwala na ograniczone wykorzystanie materiałów chronionych prawem autorskim bez zgody właściciela, pod warunkiem spełnienia określonych kryteriów (np. cel edukacyjny, transformacyjne użycie, brak wpływu na rynek). W kontekście trenowania AI, jak w przypadku Llama 3, kluczowe będzie, czy sąd uzna to za legalne zastosowanie.
Czy AI będzie uczciwa? Może polski PLLuM będzie wzorcem
W tle pojawia się wizja przyszłości:
- subskrypcyjna biblioteka dla AI („Spotify dla książek”?),
- wyspecjalizowane modele AI trenowane tylko na legalnych danych (Mam Startup),
- licencje i tantiemy dla autorów (Olesinski.com),
- systemy do śledzenia źródeł danych w AI (arXiv).
- fundusz emerytalny dla autorów.
W Polsce przykład daje PLLUM – legalny model AI, który oferuje autorom umowy licencyjne. Czyli da się. Pytanie tylko, czy giganci pójdą tą drogą?
PLLuM: Polska alternatywa dla „dzikiego zachodu” . Projekt PLLuM (Polish Large Language Universal Model) ma być pierwszym dużym modelem językowym w języku polskim, rozwijanym na zasadach etyki, transparentności i legalności. Za projektem stoją m.in. Politechnika Wrocławska, NASK, Instytut Podstaw Informatyki PAN, Ośrodek Przetwarzania Informacji – Państwowy Instytut Badawczy, Uniwersytet Łódzki oraz Instytut Slawistyki PAN.
Pomysł? Zamiast kraść książki z torrentów, zaprosić autorów i wydawców do współpracy, podpisać legalne umowy licencyjne, a przy okazji stworzyć system śledzenia źródeł tekstów, na których model się uczy. Taki system byłby globalnym precedensem. PLLuM ma już zapewnione 14,5 mln zł publicznego finansowania, a kolejne 19 mln zł ma trafić na jego wdrożenie w administracji publicznej. Model będzie udostępniany na otwartej licencji do zastosowań naukowych i niekomercyjnych, a wersje komercyjne mają korzystać z licencjonowanych treści oraz danych zgodnych z unijnym prawem.
Wicepremier i minister cyfryzacji, Krzysztof Gawkowski, podkreślił znaczenie projektu słowami: "PLLuM to dowód na to, że możemy rozwijać nowoczesne technologie na własnych warunkach, w naszym języku, z korzyścią dla obywatelek i obywateli."
Brzmi dobrze? Brzmi świetnie. Ale… jest haczyk. W budżecie nie zaplanowano środków na opłacenie autorów za ich teksty. Czyli twórcom się mówi: "chcesz – daj, ale za darmo". To stawia pod znakiem zapytania, czy naprawdę uda się przekonać większą liczbę pisarzy do oddania swoich dzieł do treningu AI, nawet jeśli idea jest szczytna.
Co możemy zrobić jako czytelnicy i twórcy?
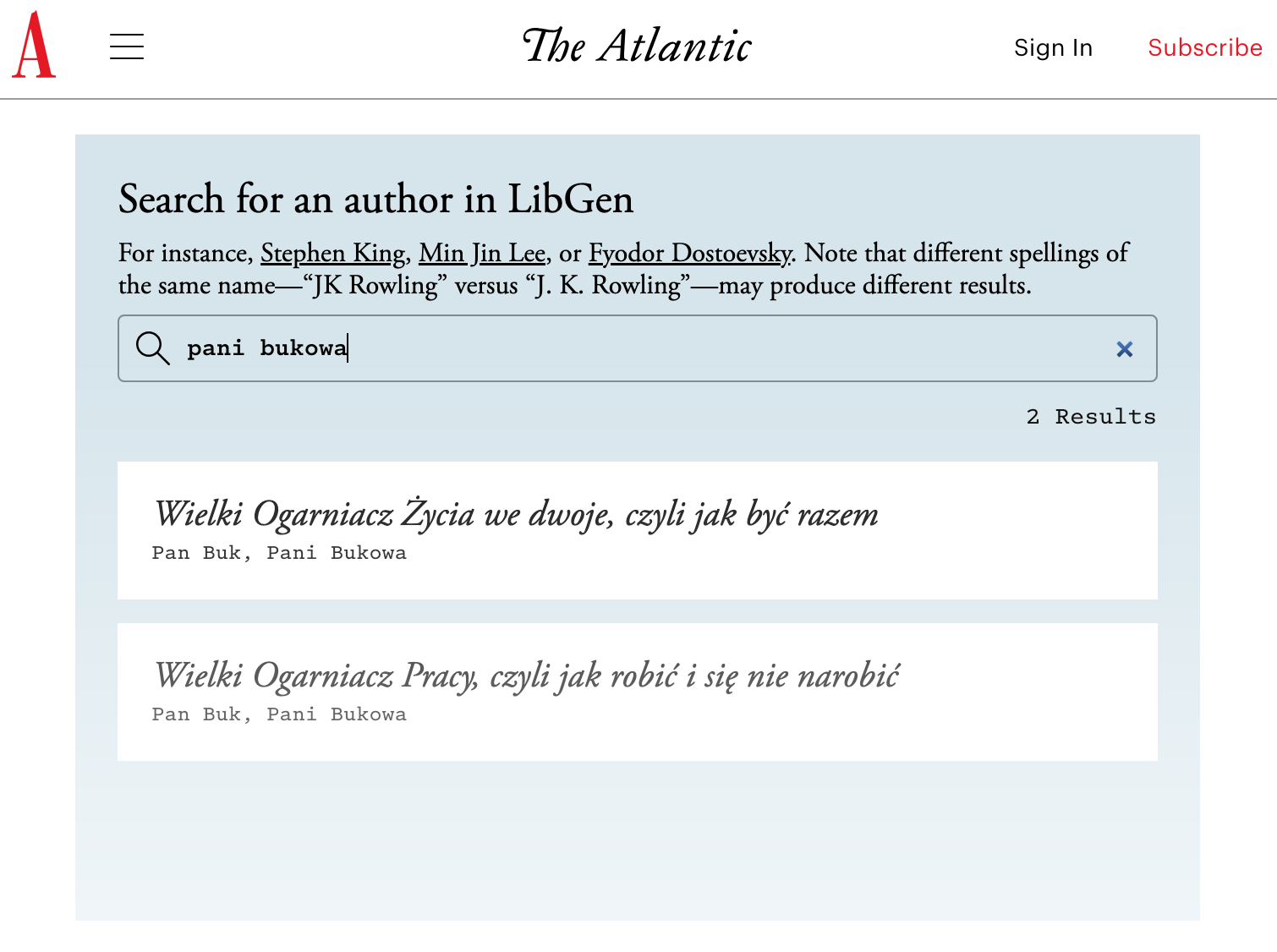
- Sprawdź, czy Twoje książki są w Books3 https://www.theatlantic.com/technology/archive/2025/03/search-libgen-data-set/682094/
- Wesprzyj twórców, którzy domagają się sprawiedliwości.
- Nie daj się zwieźć bajce, że AI to czysta technologia – to też polityka, władza i kasa.
I na koniec pytania, które zostają: Czy AI będzie rozwijana na kradzionych książkach, czy na uczciwych umowach? Czy Polska zareaguje jako państwo, czy tylko jako społeczność pisarzy? I co zrobi Zuckerberg, gdy skończą się wymówki?
Słowniczek AI
- Token – najmniejszy fragment tekstu używany przez AI (słowo lub jego część).
- Korpus treningowy – ogromny zbiór danych (tekstów), na których uczony jest model AI..
- Books3 – to dataset, czyli konkretna paczka danych Stworzony przez projekt ThePile / EleutherAI jako część otwartego korpusu treningowego do AI. Zawierał ok. 183 000 książek w języku angielskim. Źródło danych Books3? → LibGen (Library Genesis) – to właśnie stamtąd pobrano pliki PDF/EPUB. Books3 został wykorzystany m.in. w treningu LLaMA 1 i 2 (Meta) oraz StableLM (Stability AI). Został usunięty z HuggingFace (platformy do dzielenia się danymi do AI) po pozwach związanych z naruszeniem praw autorskich.
- LibGen – to piracka biblioteka Rosyjskiego pochodzenia, działa od około 2008 roku. Zawiera miliony książek naukowych, podręczników, beletrystyki – pobranych nielegalnie. Jest jedną z największych pirackich baz danych na świecie i działa do dziś w ukryciu (m.in. przez sieć TOR)
- Unia Literacka to stowarzyszenie polskich pisarzy i pisarek, założone w 2017 roku, które działa na rzecz ochrony ich praw, warunków pracy i pozycji zawodowej. Powstała z inicjatywy samych twórców, bez wsparcia państwowego, i do dziś utrzymuje się głównie ze składek członkowskich, dbając przy tym o niezależność. Choć formalnie reprezentuje osoby zrzeszone, jej działania – jak opracowanie wzorów umów, interwencje medialne czy stanowiska legislacyjne – służą całemu środowisku literackiemu. W czasie pandemii COVID-19 zasłynęła ogólnopolską akcją pomocową dla pisarzy, którzy z dnia na dzień stracili dochody z honorariów i spotkań autorskich. Dzięki zrzutce i współpracy z Biblioteką Narodową, Unia rozdzieliła setki mikrograntów dla najbardziej potrzebujących autorów. W sprawie Books3 i trenowania AI na książkach bez zgody autorów, Unia Literacka jako pierwsza publicznie zaapelowała do twórców o sprawdzenie, czy ich dzieła zostały „zajumane” przez Metę. Wymownie zapytała: „Czy Twoje książki też ukradli?”, dając sygnał, że temat nie może zostać przemilczany. W świecie, w którym korporacje szkolą swoje AI na cudzym dorobku,
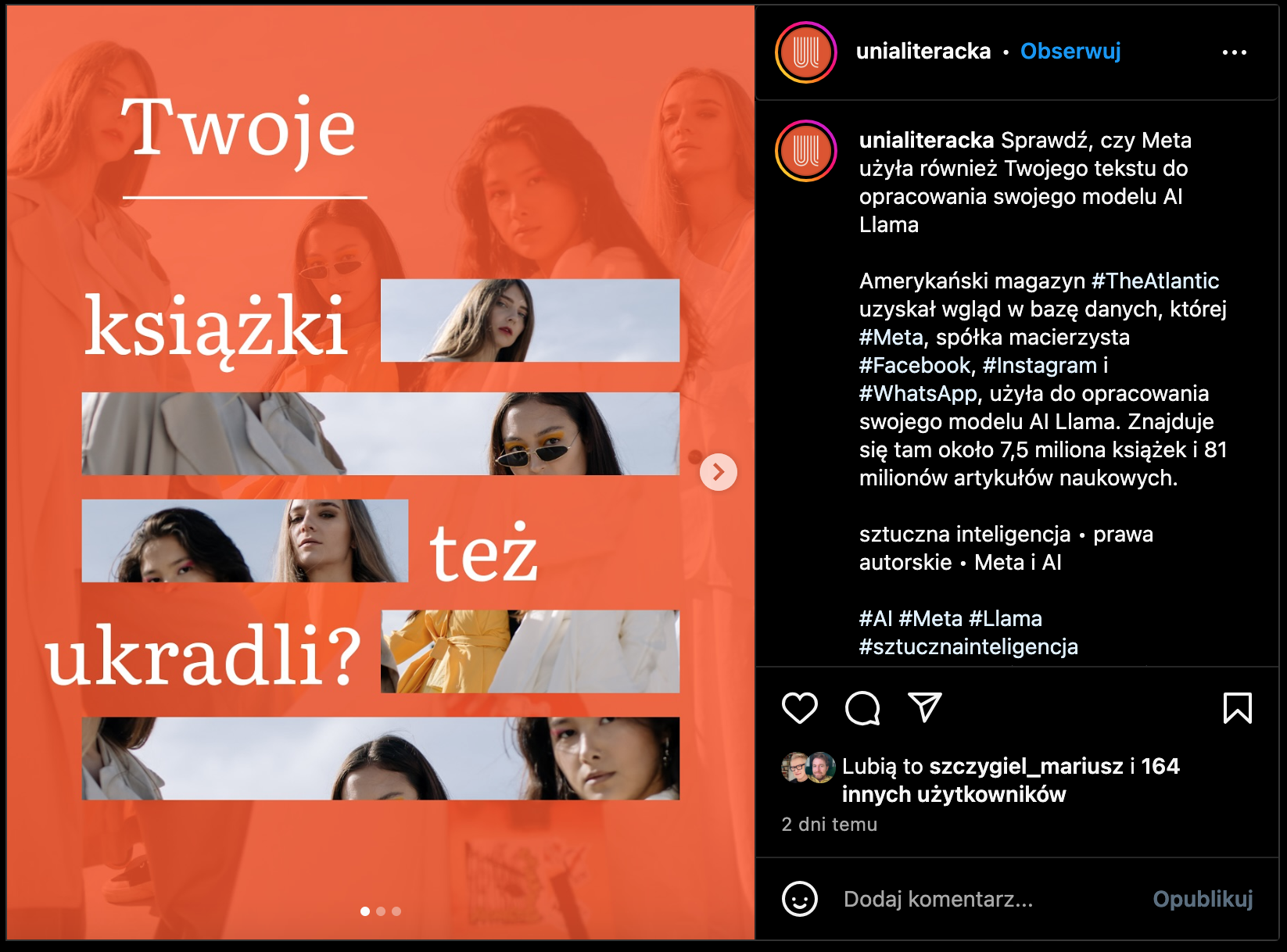
Podyskutuj na Instagramie Uni LIterackiej: https://www.instagram.com/unialiteracka/
Źródło:
Wyborcza.pl / Wojciech Szot / "Największa kradzież dzieł w historii ludzkości". Zuckerberg użył milionów spiraconych książek
Aktualizacja: 06/04/2025 22:56

Reklama
Podziel się swoją opinią
Twoje zdanie jest ważne jednak nie może ranić innych osób lub grup.






Reklama
Reklama





Reklama
Reklama
Reklama
Komentarze opinie